折腾好几个小时只做出了一道 Misc 题(虽然拿了一血),但总归还是太菜了。
题目
题面「听听这是什么」,题给文件有 hint.png、嘘.wav 以及 this is our secret.bmp。
题解
先看 hint.png,这不是常见的 QR Code,在「二维码」的 Wikipedia 页面中可以找到目前常用的二维码,其中可以靠特征识别出这个是「汉信码」。
使用在线工具可以识别这个二维码,得到:
1 | length:189 |
这已经很明示了,this is our secret.bmp 是 OurSecret 软件生成的加密文件,使用 0urS3cret 作为密码在软件中解密后得到 haha.txt,内容如下:
1 | abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890_}{-?! |
看起来这是个字符表。最后只剩下一个 WAV 文件了,直接先整个频谱图看看:
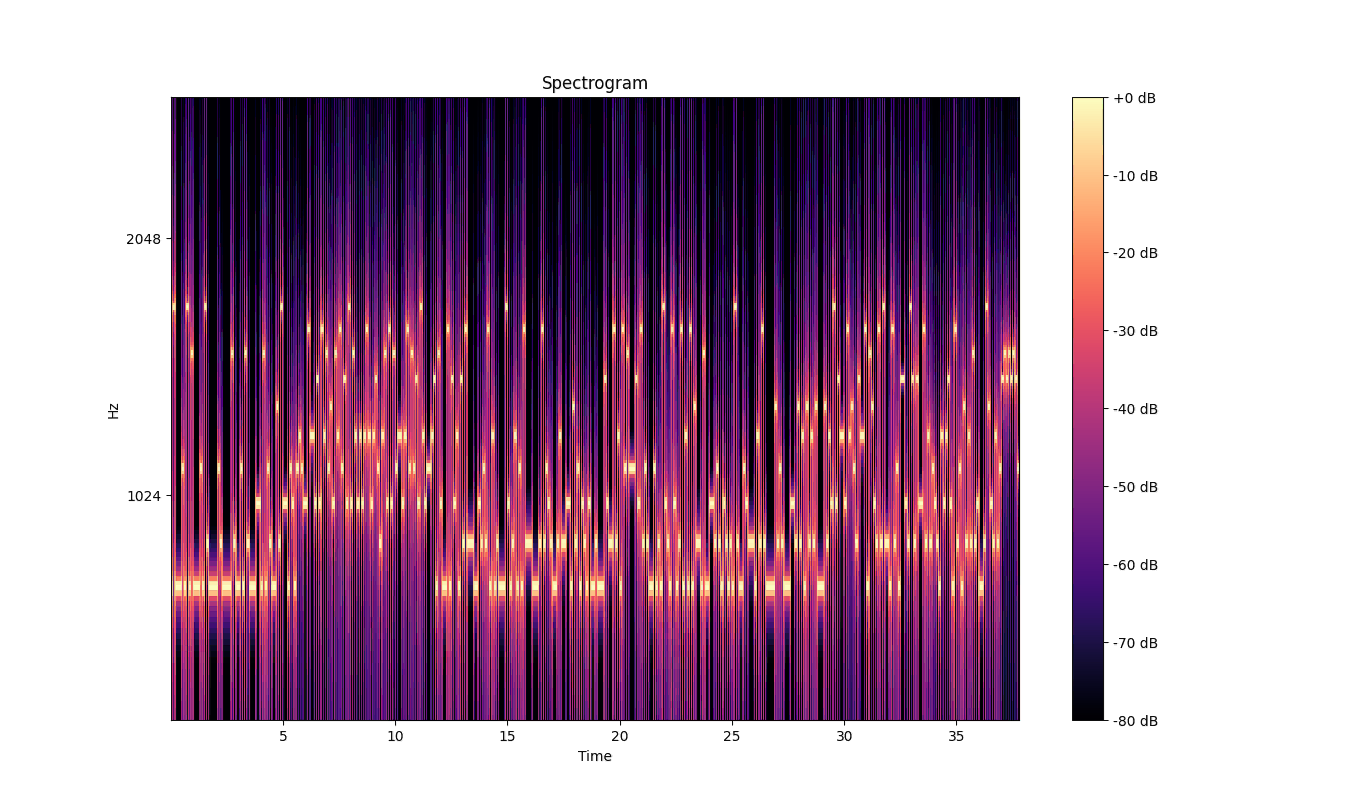
不难看出主要出场的只有 10 个频率,直接进行代码分析:
1 | import librosa |
分析输出,基本上可以看出每 0.1s 维持一个频率。盲猜每 0.2s 表示一个字符(10 个频率从低到高 0~9,两位数直接在字符表中下标找字符),稍微修改下结尾的代码:
1 | result = [] |
得到结果:
1 | jadjhadjkadkahkdhkawhdkftwduIGCSACVJBWKDBQQWQUFVCBIQWLKDQHUhuigygslkcnsebajuodilkasnvaolwfnckubagvsoiLHKCnkdbjviuseiflhawnkvbjkdvleskafnkawpofopafoDASCTF{Wh1stling_t0_Convey_informat1on!!!} |
其中有 Flag:DASCTF{Wh1stling_t0_Convey_informat1on!!!}
This article is authored by luoingly and is licensed under CC BY-NC 4.0
Permalink: https://luoingly.top/post/dasctf-cbctf-2023-justlisten-writeup/