只有第一周的题目,后面被拉去出题组了。
没有写题解的题不一定是不会做,很大概率是觉得不是特别有意思所以懒得做(写)了。
根本进不去啊! 悄悄告诉你: flag 在 flag.basectf.fun
进不去!怎么想都进不去吧?
直接一手 dig:
1 2 3 4 5 6 7 8 9 $ dig -t TXT flag.basectf.fun ; <<>> DiG [REDACTED] <<>> -t TXT flag.basectf.fun ;; ... [REDACTED] ... ;; ANSWER SECTION: flag.basectf.fun. 600 IN TXT "FLAG: BaseCTF{h0h0_th1s_15_dns_rec0rd}" ;; ... [REDACTED] ...
捂住 X 只耳 BaseCTF 解题指定 BGM。
题目给定一个音频文件,你会发现无论是听上去(指直接播放)、看上去(指直接看十六进制)或是莽上去(指把能想到的常见音频隐写工具全试一遍)都没有异常。事实上,该音频的左声道与右声道有着细微的差别。
将音频丢入 Auduacity,先把左右声道分开:
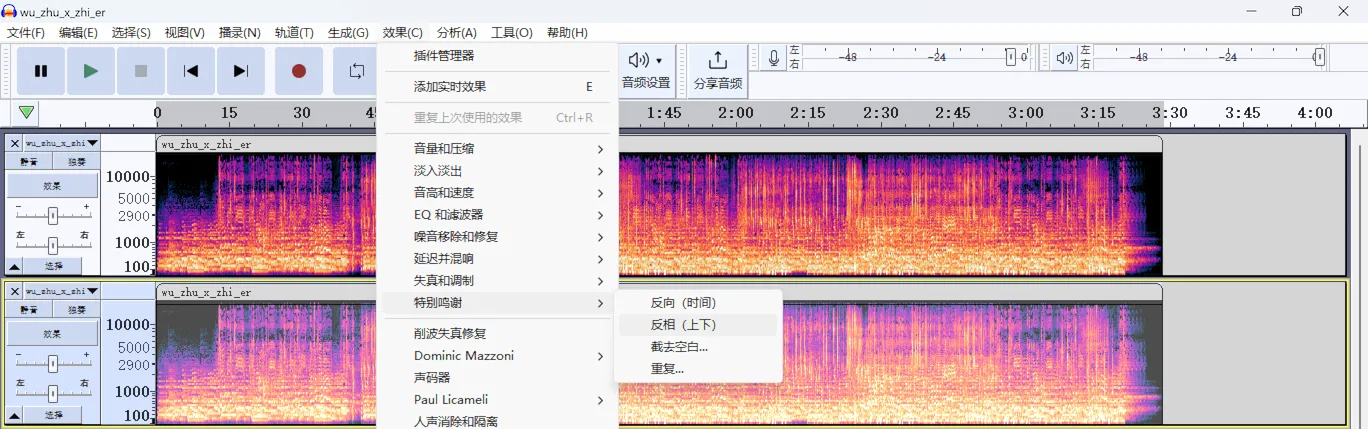
然后选中其中一个声道,应用上下反相效果:
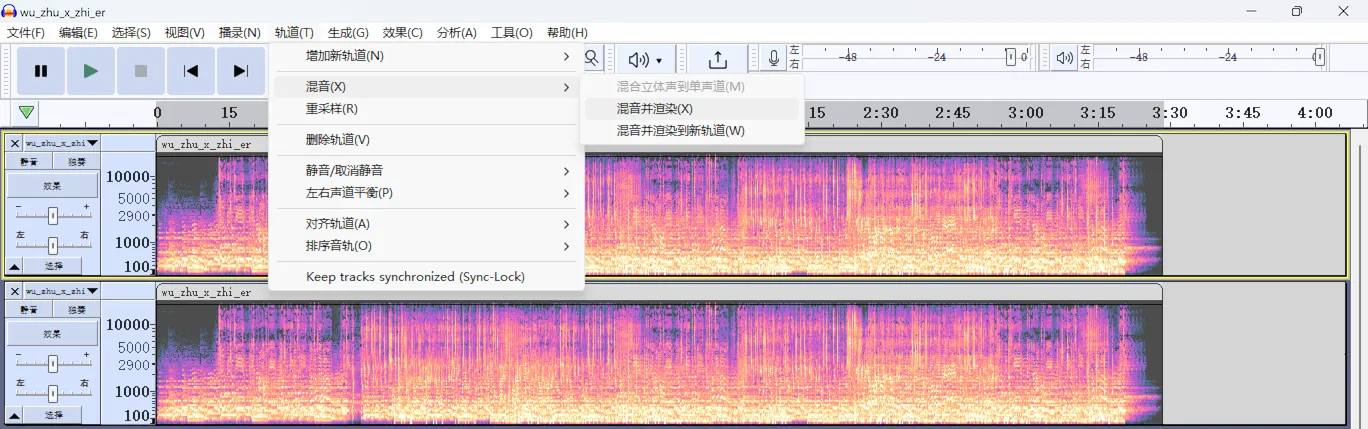
接着选中两个声道,合并它们:
现在你应该很熟悉这是什么东西了:
人生苦短,我用 Python Python 语法大杂烩,下面有请 ChatGPT 帮我写一下详细内容:
题目给定的代码实际上是在定义一组验证规则,我们可以通过逆向思考,逐步构造满足所有条件的字符串。下面是针对每个条件的解析,以及在这个条件下可以确定的字符串部分。
长度检查 :if len(flag) != 38
字符串长度必须是 38。 ??????????????????????????????????????前缀检查 :if not flag.startswith('BaseCTF{')
字符串必须以 BaseCTF{ 开头。 BaseCTF{??????????????????????????????特定位置字符检查 :if flag.find('Mp') != 10
在索 10 的地方必须找到 Mp,因此索 10 开始的地方应该是 Mp。 BaseCTF{??Mp??????????????????????????后缀检查 :if flag[-3:] * 8 != '3x}3x}3x}3x}3x}3x}3x}3x}'
最后三个字符必须是 3x}。 BaseCTF{??Mp???????????????????????3x}最后一个字符 ASCII 检查 :if ord(flag[-1]) != 125
最后一个字符的 ASCII 值应该是 125,即 }。 字符计数检查 :if flag.count('_') // 2 != 2
下划线字符的个数除以 2 后必须等于 2,也就是说总共必须有 4 个下划线。 分段长度检查 :if list(map(len, flag.split('_'))) != [14, 2, 6, 4, 8]
按照下划线分割后,每段的长度分别应该是 14, 2, 6, 4, 8。 BaseCTF{??Mp??_??_??????_????_?????3x}间隔字符检查 :if flag[12:32:4] != 'lsT_n'
从索引 12 到 32,每隔 4 个字符取一次,这些字符应该拼成 lsT_n。 BaseCTF{??Mpl?_?s_??T???_???n_?????3x}Emoji 连接的大写检查 :if '😺'.join([c.upper() for c in flag[:9]]) != 'B😺A😺S😺E😺C😺T😺F😺{😺S'
前 9 个字符转换为大写后应该是 BASECTF{S。 数值幂运算检查 :if not flag[-11].isnumeric() or int(flag[-11]) ** 5 != 1024
倒数第 11 个字符必须是数字且其五次方等于 1024,因此这个数字是 4。 BaseCTF{??Mpl?_?s_??T???_??4n_?????3x}Base64 编码检查 :if base64.b64encode(flag[-7:-3].encode()) != b'MG1QbA=='
倒数第 7 到第 3 个字符的 Base64 编码结果必须是 MG1QbA==。 BaseCTF{??Mpl?_?s_??T???_??4n_?0mPl3x}倒序切片检查 :if flag[::-7].encode().hex() != '7d4372733173'
字符串每隔 7 个字符倒序排列后,其十六进制结果必须是 7d4372733173。 BaseCTF{?1Mpl?_?s_??T??r_??4n_C0mPl3x}集合检查 :if set(flag[12::11]) != {'l', 'r'}
从索引 12 开始每隔 11 个字符取一次,这些字符的集合必须是 {'l', 'r'}。 子串编码检查 :if flag[21:27].encode() != bytes([116, 51, 114, 95, 84, 104])
索引 21 到 27 的子串必须是编码后的 [116, 51, 114, 95, 84, 104],即 t3r_Th。 BaseCTF{?1Mpl?_?s_??Tt3r_Th4n_C0mPl3x}加权和检查 :if sum(ord(c) * 2024_08_15 ** idx for idx, c in enumerate(flag[17:20])) != 41378751114180610
计算从索 17 到 20 的字符加权和,要求结果等于 41378751114180610。 BaseCTF{?1Mpl?_?s_BeTt3r_Th4n_C0mPl3x}字符类型检查 :if not all([flag[0].isalpha(), flag[8].islower(), flag[13].isdigit()])
第 1 个字符必须是字母,第 9 个字符必须是小写字母,第 14 个字符必须是数字。 BaseCTF{s1Mpl?_?s_BeTt3r_Th4n_C0mPl3x}字符串替换检查 :if '{whats} {up}'.format(whats=flag[13], up=flag[15]).replace('3', 'bro') != 'bro 1'
字符替换后应该得到 bro 1。 BaseCTF{s1Mpl3_1s_BeTt3r_Th4n_C0mPl3x}SHA-1哈希检查 :if hashlib.sha1(flag.encode()).hexdigest() != 'e40075055f34f88993f47efb3429bd0e44a7f479'
整个字符串的 SHA-1 哈希值必须等于 e40075055f34f88993f47efb3429bd0e44a7f479。 基于这些条件,可以逐步构造出目标字符串,可以直接运行脚本来验证它是否符合所有条件。
Ez Xor ChatGPT 是优秀的解混淆工具。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <bits/stdc++.h> using namespace std;int64_t KeyStream (int64_t key, int64_t stream, int length) for (int i = 0 ; i < length; ++i) { *reinterpret_cast <uint8_t *>(stream + i) = i ^ *reinterpret_cast <uint8_t *>(key + i % 3 ); } return 1 ; } int64_t encrypt (int64_t input, int64_t output, int length) for (int i = 0 ; i < length; ++i) { *reinterpret_cast <uint8_t *>(output + i) ^= *reinterpret_cast <uint8_t *>(input + length - i - 1 ); } return 1 ; } int64_t CheckFlag (int64_t original, int64_t encrypted, int length) for (int i = 0 ; i < length; ++i) { if (*reinterpret_cast <uint8_t *>(original + i) != *reinterpret_cast <uint8_t *>(encrypted + i)) { return 0 ; } } return 1 ; } int main (int argc, const char **argv, const char **envp) int64_t keyStreamBuffer[3 ] = {0 }; char inputBuffer[8 ] = {0 }; char expectedFlag[24 ] = {0 }; char key[] = "\"@;%" ; unsigned int inputLength = 0 ; unsigned int flagLength = strlen (expectedFlag); *reinterpret_cast <int64_t *>(expectedFlag) = 0x1D0B2D2625050901 ; *reinterpret_cast <int64_t *>(expectedFlag + 8 ) = 0x673D491E20317A24 ; *reinterpret_cast <int64_t *>(expectedFlag + 16 ) = 0x34056E2E2508504D ; cout << "Please input your answer: " ; cin >> inputBuffer; inputLength = strlen (inputBuffer); if (inputLength == 28 ) { int64_t key = 7499608 ; KeyStream (reinterpret_cast <int64_t >(&key), reinterpret_cast <int64_t >(keyStreamBuffer), 28 ); encrypt (reinterpret_cast <int64_t >(keyStreamBuffer), reinterpret_cast <int64_t >(inputBuffer), inputLength); if (CheckFlag (reinterpret_cast <int64_t >(inputBuffer), reinterpret_cast <int64_t >(expectedFlag), flagLength)) { cout << "You are good!" << endl; } else { cout << "It's not the flag!" << endl; } } else { cout << "The length was wrong." << endl; } return 0 ; }
ChatGPT 这写法… 算了,也不是不能看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from Crypto.Util.number import long_to_bytesdef keystream (key, length ): stream = [0 ] * length for i in range (length): stream[i] = i ^ key[i % 3 ] return bytes (stream) def encrypt (input_data, key, length ): encrypted = list (input_data) for i in range (length): encrypted[i] ^= key[length - i - 1 ] return bytes (encrypted) cipher = \ long_to_bytes(0x1D0B2D2625050901 )[::-1 ] +\ long_to_bytes(0x673D491E20317A24 )[::-1 ] +\ long_to_bytes(0x34056E2E2508504D )[::-1 ] +\ b"\"@;%" key = long_to_bytes(7499608 )[::-1 ] key_stream = keystream(key, 28 ) flag = encrypt(cipher, key_stream, 28 ) print (flag)
ez_maze 真就一迷宫。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include <bits/stdc++.h> using namespace std;const char maze[] = "x$$$$$$$$$$$$$$" "&&&&&&$$$$$$$$$" "&$&$$&$$&&&&&$$" "&$&$$$&&$$$$&$$" "&$$$&&&$$$$$&$$" "&$$$&$&&$&$$$$$" "&$$$&$&$$&&&$$$" "&&&&&$&&&&$&$$$" "$$$$$$&&&&&&$$$" "$$$$$$&$$$$$$$$" "$$$&&&&$$&&&$$$" "$$$&&&&&&&$$$$$" "$$$$$$$$$&$$&$$" "$$$$$$$$$&$&$$$" "$$$$$$&&&&&&&&y" ; int err_out_of_bounds () cout << "Invalid move: out of bounds!" << endl; return -1 ; } int err_invalid_input () cout << "Invalid input!" << endl; return -1 ; } int main () cout << "Can you walk the maze???" << endl; cout << "Take the shortest path to the finish line.OK?" << endl; cout << "Show your time!!!" << endl; char path[35 ]; memset (path, 0 , sizeof (path)); cin >> path; int pos = 0 ; for (int i = 0 ; path[i]; ++i) { char move = path[i]; if (move == 'd' ) { if (pos % 15 == 14 ) return err_out_of_bounds (); ++pos; } else if (move > 'd' ) { if (move == 's' ) { if (pos > 209 ) return err_out_of_bounds (); pos += 15 ; } else { if (move != 'w' ) return err_invalid_input (); if (pos <= 14 ) return err_out_of_bounds (); pos -= 15 ; } } else { if (move != 'a' ) return err_invalid_input (); if (!(pos % 15 )) return err_out_of_bounds (); --pos; } if (maze[pos] == '$' ) { cout << "Invalid move: hit a wall!" << endl; return -1 ; } if (maze[pos] == 'y' ) { cout << "You win!" << endl; cout << "plz BaseCTF{lower.MD5{your path}} by 32bit" << endl; return 0 ; } } cout << "You didn't reach the end." << endl; return 0 ; }
x 是起点 y 是终点,$ 是墙,& 是路。自己看着迷宫走一下就行了。
BasePlus Base64,但是自己指定了字符表并且还加了个 XOR:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <iostream> #include <string> #include <cstring> using namespace std;const string Secret = "/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC" ;size_t Encode (const char *input, char *output) int inputLength = strlen (input); if (inputLength <= 0 ) return 0 ; size_t outputIndex = 0 ; int inputIndex = 0 ; while (inputIndex < inputLength) { unsigned char temp[3 ] = {0 }; int tempLength = 0 ; for (int i = 0 ; i < 3 && inputIndex < inputLength; ++i) { temp[i] = input[inputIndex++]; ++tempLength; } output[outputIndex++] = Secret[(temp[0 ] >> 2 ) & 0x3F ]; output[outputIndex++] = Secret[((temp[0 ] & 0x03 ) << 4 ) | ((temp[1 ] >> 4 ) & 0x0F )]; output[outputIndex++] = Secret[((temp[1 ] & 0x0F ) << 2 ) | ((temp[2 ] >> 6 ) & 0x03 )]; output[outputIndex++] = Secret[temp[2 ] & 0x3F ]; for (int i = 0 ; i < 4 ; ++i) output[outputIndex - 4 + i] ^= 0xE ; } output[outputIndex] = '\0' ; return outputIndex; } size_t Decode (const char *input, char *output) size_t inputLength = strlen (input); if (inputLength % 4 != 0 ) return 0 ; size_t outputIndex = 0 ; char decoded[4 ]; for (size_t i = 0 ; i < inputLength; i += 4 ) { for (int j = 0 ; j < 4 ; ++j) decoded[j] = input[i + j] ^ 0xE ; int index1 = Secret.find (decoded[0 ]); int index2 = Secret.find (decoded[1 ]); int index3 = Secret.find (decoded[2 ]); int index4 = Secret.find (decoded[3 ]); if (index1 == string::npos || index2 == string::npos || index3 == string::npos || index4 == string::npos) return 0 ; output[outputIndex++] = (index1 << 2 ) | (index2 >> 4 ); if (decoded[2 ] != Secret[64 ]) output[outputIndex++] = ((index2 & 0x0F ) << 4 ) | (index3 >> 2 ); if (decoded[3 ] != Secret[64 ]) output[outputIndex++] = ((index3 & 0x03 ) << 6 ) | index4; } output[outputIndex] = '\0' ; return outputIndex; } int main () char decodedOutput[100 ]; const char *input = "lvfzBiZiOw7<lhF8dDOfEbmI]i@bdcZfEc^z>aD!" ; size_t encodedLength = Decode (input, decodedOutput); cout << "Decoded: " << decodedOutput << endl; return 0 ; }
麻烦 ChatGPT 写一下 Decoder 又不是什么难事。